本章内容
最近在学习 C++11/14/17/20 的新特性,本章为学习笔记。
序言
参考文档:
主要包含内容:右值引用、智能指针、Lambda 表达式...
右值引用
右值和左值的区别
1
2
| int a = 0;
int b = rand();
|
直观理解:左值在等号左边,右值在等号右边。
深入理解:左值有名称,可以获得其内存地址,而右值没有名称,不能获取其地址。
背景
将亡值(xvalue, expiring value),是 C++11
为了引入右值引用而提出的概念(因此在传统 C++ 中,
纯右值和右值是同一个概念),也就是即将被销毁、却能够被移动的值。
将亡值可能稍有些难以理解,我们来看这样的代码:
1
2
3
4
5
6
| std::vector<int> foo() {
std::vector<int> temp = {1, 2, 3, 4};
return temp;
}
std::vector<int> v = foo();
|
在这样的代码中,就传统的理解而言,函数 foo 的返回值
temp 在内部创建然后被赋值给 v, 然而
v 获得这个对象时,会将整个 temp
拷贝一份,然后把 temp 销毁,如果这个 temp
非常大, 这将造成大量额外的开销(这也就是传统 C++
一直被诟病的问题)。在最后一行中,v 是左值、
foo() 返回的值就是右值(也是纯右值)。但是,v
可以被别的变量捕获到, 而 foo()
产生的那个返回值作为一个临时值,一旦被 v
复制后,将立即被销毁,无法获取、也不能修改。
而将亡值就定义了这样一种行为:临时的值能够被识别、同时又能够被移动。
在 C++11 之后,编译器为我们做了一些工作,此处的左值 temp
会被进行此隐式右值转换, 等价于
static_cast<std::vector<int>
&&>(temp),进而此处的 v 会将
foo 局部返回的值进行移动。
也就是后面我们将会提到的移动语义。
面向对象的效率问题
编译下面代码,同时需要关闭编译器的拷贝构造优化开关,需加上
-fno-elide-constructors
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
| #include <bits/stdc++.h>
using namespace std;
class Stack
{
public:
Stack(int size = 1000)
:msize(size), mtop(0)
{
cout << "Stack(int)" << endl;
mpstack = new int[size];
}
~Stack()
{
cout << "~Stack()" << endl;
delete[]mpstack;
mpstack = nullptr;
}
Stack(const Stack &src)
:msize(src.msize), mtop(src.mtop)
{
cout << "Stack(const Stack&)" << endl;
mpstack = new int[src.msize];
memcpy(mpstack, src.mpstack, sizeof(int)*mtop);
}
Stack& operator=(const Stack &src)
{
cout << "operator=" << endl;
if (this == &src)
return *this;
delete[]mpstack;
msize = src.msize;
mtop = src.mtop;
mpstack = new int[src.msize];
memcpy(mpstack, src.mpstack, sizeof(int)*mtop);
return *this;
}
int getSize()const { return msize; }
private:
int *mpstack;
int mtop;
int msize;
};
Stack GetStack(Stack &stack)
{
Stack tmp(stack.getSize());
return tmp;
}
int main()
{
Stack s;
s = GetStack(s);
return 0;
}
|
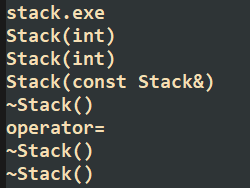 image-20220409160541045
image-20220409160541045
运行结果:
1
2
3
4
5
6
7
8
| stack.exe
Stack(int)
Stack(int)
Stack(const Stack&)
~Stack()
operator=
~Stack()
~Stack()
|
加入以下右值引用的拷贝构造函数和赋值重载:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
|
Stack(Stack &&src)
:msize(src.msize), mtop(src.mtop)
{
cout << "Stack(Stack&&)" << endl;
mpstack = src.mpstack;
src.mpstack = nullptr;
}
Stack& operator=(Stack &&src)
{
cout << "operator=(Stack&&)" << endl;
if(this == &src)
return *this;
delete[]mpstack;
msize = src.msize;
mtop = src.mtop;
mpstack = src.mpstack;
src.mpstack = nullptr;
return *this;
}
|
运行结果如下:
1
2
3
4
5
6
7
8
| stack.exe
Stack(int)
Stack(int)
Stack(Stack&&)
~Stack()
operator=(Stack&&)
~Stack()
~Stack()
|
通过使用右值引用的拷贝构造函数和赋值函数,可以提高效率。因为没有涉及任何内存的开辟和数据的拷贝,相当于直接把原对象的值拿过来了。
带右值引用参数的拷贝构造函数和复值函数又叫移动构造函数和移动赋值函数,这里的移动是指把临时量的资源移动给了当前的对象,没有发生任何新内存的开辟和数据的拷贝。
完美转发
前面我们提到了,一个声明的右值引用其实是一个左值。这就为我们进行参数转发(传递)造成了问题:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| #include <bits/stdc++.h>
void reference(int& v) {
std::cout << "左值" << std::endl;
}
void reference(int&& v) {
std::cout << "右值" << std::endl;
}
template <typename T>
void pass(T&& v) {
std::cout << "普通传参:";
reference(v);
}
int main() {
std::cout << "传递右值:" << std::endl;
pass(1);
std::cout << "传递左值:" << std::endl;
int l = 1;
pass(l);
return 0;
}
|
运行结果如下:
1
2
3
4
| 传递右值:
普通传参:左值
传递左值:
普通传参:左值
|
对于 pass(1) 来说,虽然传递的是右值,但由于
v 是一个引用,所以同时也是左值。 因此
reference(v) 会调用
reference(int&),输出『左值』。
而对于pass(l)而言,l是一个左值,为什么会成功传递给
pass(T&&) 呢?
这是基于引用坍缩规则的:在传统 C++
中,我们不能够对一个引用类型继续进行引用, 但 C++
由于右值引用的出现而放宽了这一做法,从而产生了引用坍缩规则,允许我们对引用进行引用,
既能左引用,又能右引用。但是却遵循如下规则:
| T& |
左引用 |
T& |
| T& |
右引用 |
T& |
| T&& |
左引用 |
T& |
| T&& |
右引用 |
T&& |
因此,模板函数中使用 T&&
不一定能进行右值引用,当传入左值时,此函数的引用将被推导为左值。
更准确的讲,无论模板参数是什么类型的引用,当且仅当实参类型为右引用时,模板参数才能被推导为右引用类型。
这才使得 v 作为左值的成功传递。
完美转发就是基于上述规律产生的。所谓完美转发,就是为了让我们在传递参数的时候,
保持原来的参数类型(左引用保持左引用,右引用保持右引用)。
为了解决这个问题,我们应该使用 std::forward
来进行参数的转发(传递):
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| #include <iostream>
#include <utility>
void reference(int& v) {
std::cout << "左值引用" << std::endl;
}
void reference(int&& v) {
std::cout << "右值引用" << std::endl;
}
template <typename T>
void pass(T&& v) {
std::cout << " 普通传参: ";
reference(v);
std::cout << " std::move 传参: ";
reference(std::move(v));
std::cout << " std::forward 传参: ";
reference(std::forward<T>(v));
std::cout << "static_cast<T&&> 传参: ";
reference(static_cast<T&&>(v));
}
int main() {
std::cout << "传递右值:" << std::endl;
pass(1);
std::cout << "传递左值:" << std::endl;
int v = 1;
pass(v);
return 0;
}
|
输出结果为:
1
2
3
4
5
6
7
8
9
10
| 传递右值:
普通传参: 左值引用
std::move 传参: 右值引用
std::forward 传参: 右值引用
static_cast<T&&> 传参: 右值引用
传递左值:
普通传参: 左值引用
std::move 传参: 右值引用
std::forward 传参: 左值引用
static_cast<T&&> 传参: 左值引用
|
无论传递参数为左值还是右值,普通传参都会将参数作为左值进行转发, 所以
std::move
总会接受到一个左值,从而转发调用了reference(int&&)
输出右值引用。
唯独 std::forward
即没有造成任何多余的拷贝,同时完美转发(传递)了函数的实参给了内部调用的其他函数。
std::forward 和 std::move
一样,没有做任何事情,std::move 单纯的将左值转化为右值,
std::forward
也只是单纯的将参数做了一个类型的转换,从现象上来看,
std::forward<T>(v) 和
static_cast<T&&>(v) 是完全一样的。
右值引用的场景
- 搭配容器使用
- 结合
std::move() 使用,C++11 提供了
std::move 这个方法将左值参数无条件的转换为右值,
有了它我们就能够方便的获得一个右值临时对象
- 结合
std::forward() 使用
智能指针
背景
在传统 C++
中,需要我们记得手动释放内存,但在实际编程中,很有可能因为忘记释放内存而导致泄露。所以传统的做法,对于一个对象而言,我们在构造函数的时候申请空间,而在析构函数(离开作用域的时候调用)的时候释放空间。
但即便如此,我们总有需要将对象在自由存储上分配的需求,传统 C++
要求我们使用 new 和 delete
来记得释放内存。在 C++11
中引入智能指针的概念,使用引用计数的思想,让我们不再需要关心手动释放内存。
这些智能指针包含 std::shared_ptr
、std::unique_ptr、std::weak_prt
,使用它们需要包含头文件 <memory>
std::shared_ptr
std::shared_ptr 是一种智能指针,它能够记录多少个
shared_ptr 共同指向一个对象,从而消除显式的调用
delete,当引用计数变为零的时候就会将对象自动删除。
但还不够,因为使用 std::shared_ptr 仍然需要使用
new 来调用,这使得代码出现了某种程度上的不对称。
std::make_shared 就能够用来消除显式的使用
new,所以std::make_shared
会分配创建传入参数中的对象,
并返回这个对象类型的std::shared_ptr指针。
std::shared_ptr 可以通过 get()
方法来获取原始指针,通过 reset() 来减少一个引用计数,
并通过use_count()来查看一个对象的引用计数。例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
| auto pointer = std::make_shared<int>(10);
auto pointer2 = pointer;
auto pointer3 = pointer;
int *p = pointer.get();
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl;
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl;
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl;
pointer2.reset();
std::cout << "reset pointer2:" << std::endl;
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl;
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl;
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl;
pointer3.reset();
std::cout << "reset pointer3:" << std::endl;
std::cout << "pointer.use_count() = " << pointer.use_count() << std::endl;
std::cout << "pointer2.use_count() = " << pointer2.use_count() << std::endl;
std::cout << "pointer3.use_count() = " << pointer3.use_count() << std::endl;
|
输出结果如下:
1
2
3
4
5
6
7
8
9
10
11
12
| 1.exe
pointer.use_count() = 3
pointer2.use_count() = 3
pointer3.use_count() = 3
reset pointer2:
pointer.use_count() = 2
pointer2.use_count() = 0
pointer3.use_count() = 2
reset pointer3:
pointer.use_count() = 1
pointer2.use_count() = 0
pointer3.use_count() = 0
|
std::unique_prt
std::unique_ptr
是一种独占的智能指针,它禁止其他智能指针与其共享同一个对象,从而保证代码的安全:
1
2
| std::unique_ptr<int> pointer = std::make_unique<int>(10);
std::unique_ptr<int> pointer2 = pointer;
|
虽然是独占,但是,我们可以利用 std::move
将其转移给其他的 unique_ptr,例如:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
| #include <iostream>
#include <memory>
struct Foo {
Foo() { std::cout << "Foo::Foo" << std::endl; }
~Foo() { std::cout << "Foo::~Foo" << std::endl; }
void foo() { std::cout << "Foo::foo" << std::endl; }
};
void f(const Foo &) {
std::cout << "f(const Foo&)" << std::endl;
}
int main() {
std::unique_ptr<Foo> p1(std::make_unique<Foo>());
if (p1) p1->foo();
{
std::unique_ptr<Foo> p2(std::move(p1));
f(*p2);
if(p2) p2->foo();
if(p1) p1->foo();
p1 = std::move(p2);
if(p2) p2->foo();
std::cout << "p2 被销毁" << std::endl;
}
if (p1) p1->foo();
}
|
运行结果如下:
1
2
3
4
5
6
7
8
| 2.exe
Foo::Foo
Foo::foo
f(const Foo&)
Foo::foo
p2 被销毁
Foo::foo
Foo::~Foo
|
std::weak_ptr
但 std::shared_ptr
依然存在着资源无法释放的问题。如下例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| struct A;
struct B;
struct A {
std::shared_ptr<B> pointer;
~A() {
std::cout << "A 被销毁" << std::endl;
}
};
struct B {
std::shared_ptr<A> pointer;
~B() {
std::cout << "B 被销毁" << std::endl;
}
};
int main() {
auto a = std::make_shared<A>();
auto b = std::make_shared<B>();
a->pointer = b;
b->pointer = a;
}
|
运行结果是 A, B 都不会被销毁,这是因为 a,b 内部的 pointer
同时又引用了 a,b,这使得 a,b
的引用计数均变为了 2,而离开作用域时,a,b
智能指针被析构,却只能造成这块区域的引用计数减一,这样就导致了
a,b
对象指向的内存区域引用计数不为零,而外部已经没有办法找到这块区域了,也就造成了内存泄露,如下图:
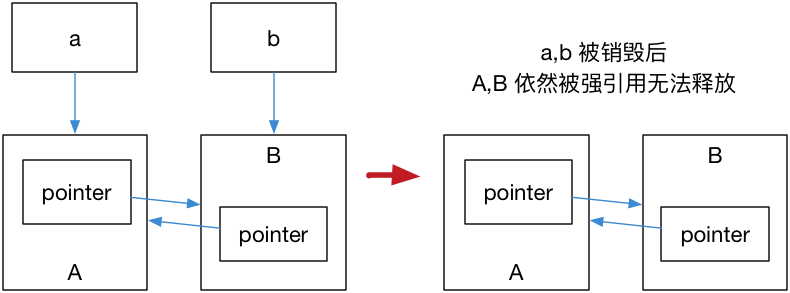
解决这个问题的办法就是使用弱引用指针
std::weak_ptr,std::weak_ptr是一种弱引用(相比较而言
std::shared_ptr
就是一种强引用)。弱引用不会引起引用计数增加,当换用弱引用时候,最终的释放流程如下图:
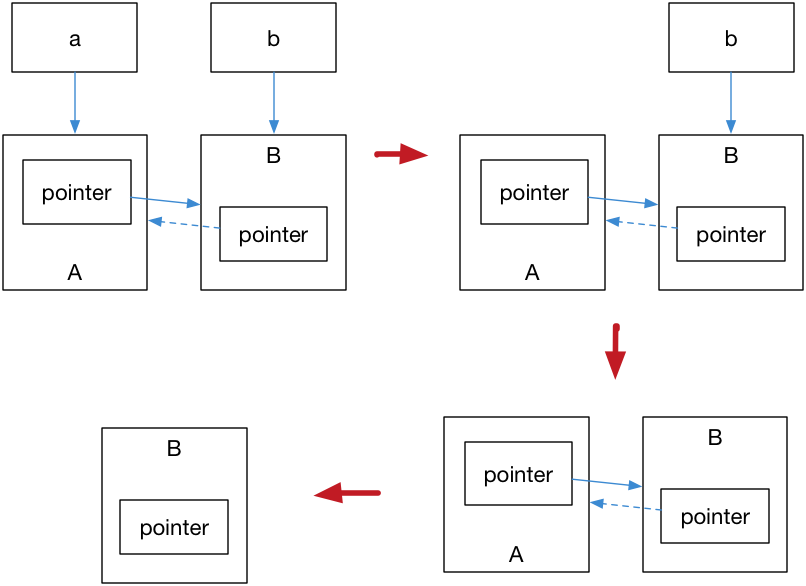
可以改写成如下例子:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| #include <bits/stdc++.h>
struct A;
struct B;
struct A {
std::weak_ptr<B> pointer;
~A() {
std::cout << "A 被销毁" << std::endl;
}
};
struct B {
std::shared_ptr<A> pointer;
~B() {
std::cout << "B 被销毁" << std::endl;
}
};
int main() {
auto a = std::make_shared<A>();
auto b = std::make_shared<B>();
a->pointer = b;
b->pointer = a;
std::cout << "count of a: " << a.use_count() << std::endl;
std::cout << "count of b: " << b.use_count() << std::endl;
return 0;
}
|
运行结果如下:
1
2
3
4
| count of a: 2
count of b: 1
B 被销毁
A 被销毁
|
并发与并行
...
Lambda表达式
Lambda 表达式是现代 C++ 中最重要的特性之一,而 Lambda
表达式,实际上就是提供了一个类似匿名函数的特性,
而匿名函数则是在需要一个函数,但是又不想费力去命名一个函数的情况下去使用的。这样的场景其实有很多很多,
所以匿名函数几乎是现代编程语言的标配。
基础
Lambda 表达式的基本语法如下:
1
2
3
| [捕获列表](参数列表) mutable(可选) 异常属性 -> 返回类型 {
}
|
上面的语法规则除了 [捕获列表]
内的东西外,其他部分都很好理解,只是一般函数的函数名被略去,
返回值使用了一个 ->
的形式进行(我们在上一节前面的尾返回类型已经提到过这种写法了)。
所谓捕获列表,其实可以理解为参数的一种类型,Lambda
表达式内部函数体在默认情况下是不能够使用函数体外部的变量的,
这时候捕获列表可以起到传递外部数据的作用。根据传递的行为,捕获列表也分为以下几种:
值捕获
与参数传值类似,值捕获的前提是变量可以拷贝,不同之处则在于,被捕获的变量在
Lambda 表达式被创建时拷贝, 而非调用时才拷贝:
1
2
3
4
5
6
7
8
9
10
11
| void lambda_value_capture() {
int value = 1;
auto copy_value = [value] {
return value;
};
value = 100;
auto stored_value = copy_value();
std::cout << "stored_value = " << stored_value << std::endl;
}
|
引用捕获
与引用传参类似,引用捕获保存的是引用,值会发生变化。
1
2
3
4
5
6
7
8
9
10
11
| void lambda_reference_capture() {
int value = 1;
auto copy_value = [&value] {
return value;
};
value = 100;
auto stored_value = copy_value();
std::cout << "stored_value = " << stored_value << std::endl;
}
|
隐式捕获
手动书写捕获列表有时候是非常复杂的,这种机械性的工作可以交给编译器来处理,这时候可以在捕获列表中写一个
& 或 =
向编译器声明采用引用捕获或者值捕获。
总结一下,捕获提供了 Lambda
表达式对外部值进行使用的功能,捕获列表的最常用的四种形式可以是:
- [] 空捕获列表
- [name1, name2, ...] 捕获一系列变量
- [&] 引用捕获, 让编译器自行推导引用列表
- [=] 值捕获, 让编译器自行推导值捕获列表
表达式捕获
这部分内容需要了解右值引用以及智能指针
上面提到的值捕获、引用捕获都是已经在外层作用域声明的变量,因此这些捕获方式捕获的均为左值,而不能捕获右值。
C++14
给与了我们方便,允许捕获的成员用任意的表达式进行初始化,这就允许了右值的捕获,
被声明的捕获变量类型会根据表达式进行判断,判断方式与使用
auto 本质上是相同的:
1
2
3
4
5
6
7
8
9
10
11
| #include <iostream>
#include <memory>
#include <utility>
void lambda_expression_capture() {
auto important = std::make_unique<int>(1);
auto add = [v1 = 1, v2 = std::move(important)](int x, int y) -> int {
return x+y+v1+(*v2);
};
std::cout << add(3,4) << std::endl;
}
|
在上面的代码中,important 是一个独占指针,是不能够被 "="
值捕获到,这时候我们可以将其转移为右值,在表达式中初始化。
泛型 Lambda
上一节中我们提到了 auto
关键字不能够用在参数表里,这是因为这样的写法会与模板的功能产生冲突。
但是 Lambda 表达式并不是普通函数,所以 Lambda 表达式并不能够模板化。
这就为我们造成了一定程度上的麻烦:参数表不能够泛化,必须明确参数表类型。
幸运的是,这种麻烦只存在于 C++11 中,从 C++14 开始, Lambda
函数的形式参数可以使用 auto 关键字来产生意义上的泛型:
1
2
3
4
5
6
| auto add = [](auto x, auto y) {
return x+y;
};
add(1, 2);
add(1.1, 2.2);
|